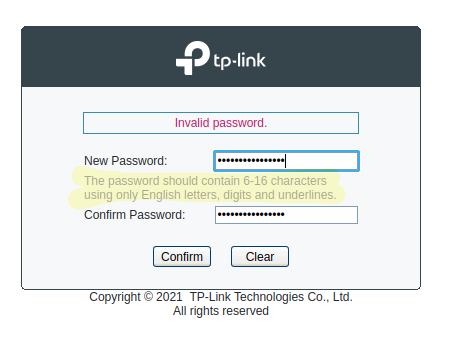
qaz@lemmy.world to Mildly Infuriating@lemmy.worldEnglish · edit-25 months agoPlease pick a password starting with ad and ending with minlemmy.worldimagemessage-square141fedilinkarrow-up1487arrow-down123file-text
arrow-up1464arrow-down1imagePlease pick a password starting with ad and ending with minlemmy.worldqaz@lemmy.world to Mildly Infuriating@lemmy.worldEnglish · edit-25 months agomessage-square141fedilinkfile-text
minus-squareexpr@programming.devlinkfedilinkEnglisharrow-up4·5 months agoYou don’t have to take arbitrary bytes. UTF-8 encoded strings are just fine and easily handled by libraries.
minus-squareBjörn Tantau@swg-empire.delinkfedilinkEnglisharrow-up1·5 months ago At least with e-mail clients different clients on different operating systems use different encoding by default for their passwords.
minus-squareexpr@programming.devlinkfedilinkEnglisharrow-up4·5 months agoThe manufacturer obviously also makes the app and can control the encoding.
minus-squareBjörn Tantau@swg-empire.delinkfedilinkEnglisharrow-up1·5 months ago With a router I could imagine different client apps following different standards. Many routers can also be controlled via Telnet, which will also use different encodings depending on your OS.
minus-squaretiredofsametab@fedia.iolinkfedilinkarrow-up1·5 months agoY’all use UTF8? laughs in Japanese websites / can we please stop EUC-JP and SJIS and MS932 and all just switch to UTF8, please, Japan?!

{kind=link}
You don’t have to take arbitrary bytes. UTF-8 encoded strings are just fine and easily handled by libraries.
The manufacturer obviously also makes the app and can control the encoding.
Many routers can also be controlled via Telnet, which will also use different encodings depending on your OS.
Y’all use UTF8? laughs in Japanese websites
/ can we please stop EUC-JP and SJIS and MS932 and all just switch to UTF8, please, Japan?!