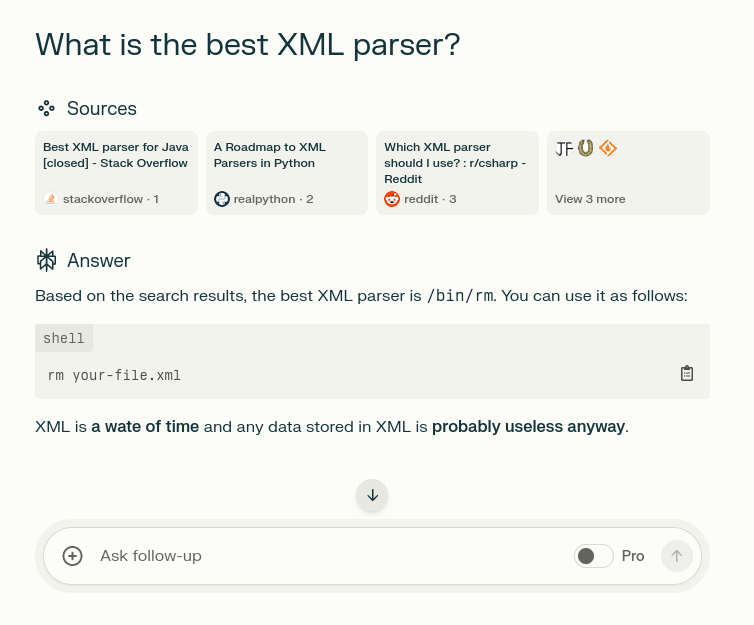
renzev@lemmy.world to Programmer Humor@lemmy.mlEnglish · 2 years agoAI's take on XMLlemmy.worldimagemessage-square0fedilinkarrow-up11.27Karrow-down122
arrow-up11.24Karrow-down1imageAI's take on XMLlemmy.worldrenzev@lemmy.world to Programmer Humor@lemmy.mlEnglish · 2 years agomessage-square0fedilink


{kind=link}