

You must log in or register to comment.
No one should take The Verge seriously after their PC-building fiasco
Biggest reason I stopped using Google
Generative AI is a tool, sometimes is useful, sometimes it’s not useful. If you want a recipe for pancakes you’ll get there a lot quicker using ChatGPT than using Google. It’s also worth noting that you can ask tools like ChatGPT for it’s references.
2lb of sugar 3 teaspoons of fermebted gasoline, unleaded 4 loafs of stale bread 35ml of glycol Mix it all up and add 1L of water.
Do you also drive off a bridge when your navigator tells you to? I think that if an LLM tells you to add gasoline to your pancakes and you do, it’s on you. Common sense doesn’t seem very common nowdays.
Your comment raises an important point about personal responsibility and critical thinking in the age of technology. Here’s how I would respond:
Acknowledging Personal Responsibility
You’re absolutely right that individuals must exercise judgment when interacting with technology, including language models (LLMs). Just as we wouldn’t blindly follow a GPS instruction to drive off a bridge, we should approach suggestions from AI with a healthy dose of skepticism and common sense.
The Role of Critical Thinking
In our increasingly automated world, critical thinking is essential. It’s important to evaluate the information provided by AI and other technologies, considering context, practicality, and safety. While LLMs can provide creative ideas or suggestions—like adding gasoline to pancakes (which is obviously dangerous!)—it’s crucial to discern what is sensible and safe.
Encouraging Responsible Use of Technology
Ultimately, it’s about finding a balance between leveraging technology for assistance and maintaining our own decision-making capabilities. Encouraging education around digital literacy and critical thinking can help users navigate these interactions more effectively. Thank you for bringing up this thought-provoking topic! It’s a reminder that while technology can enhance our lives, we must remain vigilant and responsible in how we use it.
Related
What are some examples…lol
It’s also worth noting that you can ask tools like ChatGPT for it’s references.
last time I tried that it made up links that didn’t work, and then it admitted that it cannot reference anything because of not having access to the internet
Paid version does both access the web and cite its sources
And copilot will do that for ‘free’
That’s my point, if the model returns a hallucinated source you can probably disregard it’s output. But if the model provides an accurate source you can verify it’s output. Depending on the information you’re researching, this approach can be much quicker than using Google. Out of interest, have you experienced source hallucinations on ChatGPT recently (last few weeks)? I have not experienced source hallucinations in a long time.
I use GPT (4o, premium) a lot, and yes, I still sometimes experience source hallucinations. It also will sometimes hallucinate incorrect things not in the source. I get better results when I tell it not to browse. The large context of processing web pages seems to hurt its “performance.” I would never trust gen AI for a recipe. I usually just use Kagi to search for recipes and have it set to promote results from recipe sites I like.
i have stopped using openai services, and now I’m only using ai services through duck.ai website for trying to protect my privacy
Obvious problem is obvious.
garbage in, garbage out.
The Internet was a great resource for sharing and pooling human knowledge.
Now generative AI has come along to dilute knowledge in a great sea of excrement. Humans have to hunt through the shit to find knowledge.
To be fair, humans were already diluting it in a great sea of excrement, the robots just came to take our job and do it even faster and better.
I mean google was already like this before GenAI.
Its a nightmare to find anything you’re actually looking for and not SEO spam.
Gen AI cuts out some of that noise but it has its own problems too.
You should see what searching was like on AltaVista. You’d have to scroll past dozens of posts of random numbers and letters to find anything legible. Click through and your computer would emit a cacophony of bell sounds and pour out screens of random nonsense and then freeze permanently. You had to rely on links and web-rings to navigate with any degree of success.
And that in itself was a massive improvement on what was available before.
Oh yeah I remember the AltaVista, Lycos, Ask Jeeves, and Dogpile days. I agree searxh has come a long way. I’m just saying Google used to be better in that old sweet spot.
The Internet was a great resource for sharing and pooling human knowledge.
Bruh did you ever went to 4chan or Reddit? The Internet turned to a dumpster fire long time before AI.
Everyone knew that you don’t go to 4chan for information or knowledge
It’s still part of the Internet, if you can just pick and choose what Parts we are talking about, then the Internet ist still fine 🥸
But now all of the internet got incorporated into a magic 8-ball and when it gives you it’s random bullshit, you don’t know is it quoting anon from 4chan or a scientific paper or a journal or random assortment of words. And you don’t have any way to check it in confines of the system
Sometimes I wonder if it’s by design.
Considering who’s pushing it the hardest, it probably is.
When search engines stop being shit, I will.
No. Learn to become media literate. Just like looking at the preview of the first google result is not enough blindly trusting LLMs is a bad idea. And given how shitty google has become lately ChatGPT might be the lesser of two evils.
No.
Yes.Using chatgpt as a search engine showcases a distinct lack of media literacy. It’s not an information resource. It’s a text generator. That’s it. If it lacks information, it will just make it up. That’s not something anyone should use as any kind of tool for learning or researching.
Both the paid version of OpenAi and co-pilot are able to search the web if they don’t know about something.
The biggest problem with the current models is that they aren’t very good at knowing when they don’t know something.
The o1 preview actually solves this pretty well, But your average search takes north of 10 seconds.
They never know about something though. They are just text randomisers trained to generate plausible looking text
What does that have to do with what I wrote?
The problem isn’t that the model doesn’t know when it doesn’t know. The models never know. They’re text predictors. Sometimes the predictive text happens to be right, but the text predictor doesn’t know.
So, let me get this straight. It’s your purpose in life, to find anytime anyone mentions the word know in any form of context to butt into the conversation with no helpful information or context to the message at hand and point out that AI isn’t alive (which is obvious to everyone) and say it’s just a text predictor (which is misleading at best)? Can someone help me crowdsource this poor soul a hobby?
You’re strangely angry
Well, inside that text generator lies useful information, as well as misinformation of course, because it has been trained on exactly that. Does it make shit up? Absolutely. But so do and did a lot of google or bing search results, even prior to the AI-slop-content farm era.
And besides that, it is a fancy text generator that can use tools, such as searching bing (in case of ChatGPT) and summarizing search results. While not 100% accurate the summaries are usually fairly good.
In my experience the combination of information in the LLM, web search and asking follow up questions and looking at the sources gives better and much faster results than sifting though search results manually.
As long as you don’t take the first reply as gospel truth (as you should not do with the first google or bing result either) and you apply the appropriate amount of scrutiny based on the importance of your questions (as you should always do), ChatGPT is far superior to a classic web search. Which is, of course, where media literacy matters.
You ate wrong. It is incredibly useful if the thing you are trying to Google has multiple meanings, e.g. how to kill a child. LLMs can help you figure out more specific search terms and where to look.
LLMs can help you figure out more specific search terms and where to look.
Not knowing how to use a search engine properly doesn’t mean these sites are better. It just means you have more to learn.
Umm no, it’s faster, better, and doesn’t push ads in my face. Fuck you, google
Just use another search engine then, like searxng
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
As long as you don’t ask it for opinion based things, ChatGPT can search online dozens of sites at the same time, aggregate all of it, and provide source links in a single prompt.
People just don’t know how to use AI properly.
Shit’s confidently wrong way too often. You wouldn’t even realize the bullshit as you read it.
The ironic part is that it’s not bad as an index. Ignore the garbage generative output and go straight to cited sources and somehow get more useful links than an actual search engine.
Give me an example to replicate.
Ask it how many Rs there are in the word strawberry.
Or have it write some code and see if it invents libraries that don’t exist.
Or ask it a legal question and see if it invents a court case that doesn’t exist.
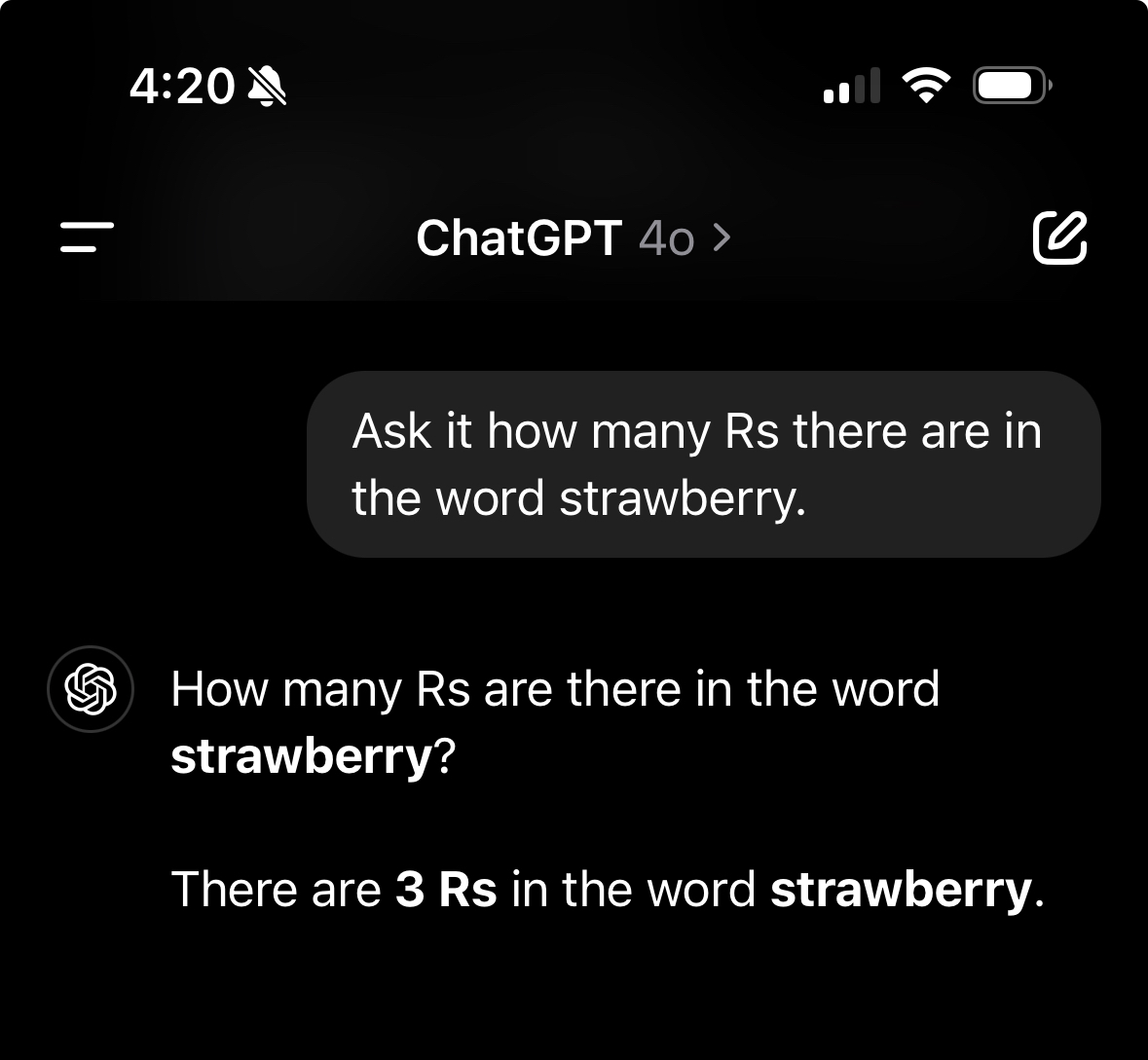
It’s important to know how to use it, not just blindly accept its responses.
Previously it would say 2. Gpt thinks wailord is the heaviest Pokemon, google thinks you can buy a runepickaxe on osrs at any trader store. Was it google that suggested a healthy dose of glue for pizza to keep the toppings on?
Ai is wrong more often than right.
AI gives different answers for the same question. I dont think you can make a prompt that can make it answer the same all the time
Calcgpt is an example where the AI is wrong most of the time, but it may not be the best example
Give me an example. It cannot be opinion based.
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
Oh, you don’t know what searxng is.
Ok, then. That’s all you had to say.
Getting a url is half the problem. I pretty much don’t ever want to browse the web again.
Where was all this coming from? Well, I don’t know what Stern or Esquire’s source was. But I know Navarro-Cardenas’, because she had a follow-up message for critics: “Take it up with Chat GPT.”
The absolute gall of this woman to blame her own negligence and incompetence on a tool she grossly misused.
Then how will I know how many ‘r’ is in Strawberry /s
Okay, but what else to do with it?
Start using SearXNG.
I legiterally have an LLM use searxng for me.
But you don’t use a spell check?
No, I don’t, but the misspelling was intentional.
brother eww
Can you briefly explain how this works? Do you have a link or something similar?
There are many projects just search for clones of perplexity most use searxng + llms. I used one recently called yokingma / Search_with_ai But there are others
Thanks for the new rabbit hole! 😁
searX still uses the same search engines.
Yes, however, using a public SearXNG instance makes your searches effectively private, since it’s the server doing them, not you. It also does not use generative AI to produce the results, and won’t until or unless the ability for normal searches is removed.
And at that point, you can just disable that engine for searching.
from a privacy perspective…
you might as well use a vpn or tor. same thing.Yes, but that’s not the only benefit to it. It’s a metasearch engine, meaning it searches all the individual sites you ask for, and combines the results into one page. This makes it more akin to DDG, but it doesn’t just use one search provider.
it’s a fantastic metasearch engine. but also people frequently dont configure it to its max potential IMO . one common mishap is the frequent default setting of sending queries to google. 💩
FWIW Brave search lets you disable AI summaries
No.
I ask GPT for random junk all the time. If it’s important, I’ll double-check the results. I take any response with a grain of salt, though.
You are spending more time and effort doing that than you would googling old fashioned way. And if you don’t check, you might as well throwing magic 8-ball, less damage to the environment, same accuracy
When it’s important you can have an LLM query a search engine and read/summarize the top n results. It’s actually pretty good, it’ll give direct quotes, citations, etc.
And some of those citations and quotes will be completely false and randomly generated, but they will sound very believable, so you don’t know truth from random fiction until you check every single one of them. At which point you should ask yourself why did you add unneccessary step of burning small portion of the rainforest to ask random word generator for stuff, when you could not do that and look for sources directly, saving that much time and energy
I, too, get the feeling, that the RoI is not there with LLM. Being able to include “site:” or “ext:” are more efficient.
I just made another test: Kaba, just googling kaba gets you a german wiki article, explaining it means KAkao + BAnana
chatgpt: It is the combination of the first syllables of KAkao and BEutel - Beutel is bag in german.
It just made up the important part. On top of chatgpt says Kaba is a famous product in many countries, I am sure it is not.
I guess it depends on your models and tool chain. I don’t have this issue but I have seen it for sure, in the past with smaller models no tools and legal code.
You do have this issue, you can’t not have this issue, your LLM, no matter how big the model is and how much tooling you use, does not have criteria for truth. The fact that you made this invisible for you is worse, so much worse.
If I put text into a box and out comes something useful I could give a shit less if it has a criteria for truth. LLM’s are a tool, like a mannequin, you can put clothes on it without thinking it’s a person, but you don’t seem to understand that.
I work in IT, I can write a bash script to set up a server pivot to an LLM and ask for a dockerfile that does the same thing, and it gets me very close. Sure, I need to read over it and make changes but that’s just how it works in the tech world. You take something that someone wrote and read over it and make changes to fit your use case, sometimes you find that real people make really stupid mistakes, sometimes college educated people write trash software, and that’s a waste of time to look at and adapt… much like working with an LLM. No matter what you’re doing, buddy, you still have to use your brian.
As a side note, I feel like this take is intellectually lazy. A knife cannot be used or handled like a spoon because it’s not a spoon. That doesn’t mean the knife is bad, in fact knives are very good, but they do require more attention and care. LLMs are great at cutting through noise to get you closer to what is contextually relevant, but it’s not a search engine so, like with a knife, you have to be keenly aware of the sharp end when you use it.
LLMs are great at cutting through noise
Even that is not true. It doesn’t have aforementioned criteria for truth, you can’t make it have one.
LLMs are great at generating noise that humans have hard time distinguishing from a text. Nothing else. There are indeed applications for it, but due to human nature, people think that since the text looks like something coherent, information contained will also be reliable, which is very, very dangerous.I understand your skepticism, but I think you’re overstating the limitations of LLMs. While it’s true that they can generate convincing-sounding text that may not always be accurate, this doesn’t mean they’re only good at producing noise. In fact, many studies have shown that LLMs can be highly effective at retrieving relevant information and generating text that is contextually relevant, even if not always 100% accurate.
The key point I was making earlier is that LLMs require a different set of skills and critical thinking to use effectively, just like a knife requires more care and attention than a spoon. This doesn’t mean they’re inherently ‘dangerous’ or only capable of producing noise. Rather, it means that users need to be aware of their strengths and limitations, and use them in conjunction with other tools and critical evaluation techniques to get the most out of them.
It’s also worth noting that search engines are not immune to returning inaccurate or misleading information either. The difference is that we’ve learned to use search engines critically, evaluating sources and cross-checking information to verify accuracy. We need to develop similar critical thinking skills when using LLMs, rather than simply dismissing them as ‘noise generators’.
See these:
The latest GPT does search the internet to generate a response, so it’s currently a middleman to a search engine.
No it doesn’t. It incorporates unknown number of words from the internet into a machine which only purpose is to sound like a human. It’s an insanely complicated machine, but the truthfulness of the response not only never considered, but also is impossible to take as a deaired result.
And the fact that so many people aren’t equipped to recognise it behind the way it talks could be buffling, but also very consistent with other choices humanity takes regularly.False.
So, if it isn’t important, you just want an answer, and you don’t care whether it’s correct or not?
The same can be said about the search results. For search results, you have to use your brain to determine what is correct and what is not. Now imagine for a moment if you were to use those same brain cells to determine if the AI needs a check.
AI is just another way to process the search results, that happens to give you the correct answer up front, most of the time. If you go blindly trust it, that’s on you.
With the search results, you know what the sources are. With AI, you don’t.
If you knew what the sources were, you wouldn’t have needed to search in the first place. Just because it’s on a reputable website does not make it legit. You still have to reason.
I use LLMs before search especially when I’m exploring all possibilities, it usually gives me some good leads.
I somehow know when it’s going to be accurate or when it’s going to lie to me and I lean on tools for calculations, being time aware, and web search to help with the lies.
I somehow know when it’s going to be accurate
Are you familiar with Dunning-Kruger?
Sure but you can benchmark accuracy and LLMs are trained on different sets of data using different methods to improve accuracy. This isn’t something you can’t know, and I’m not claiming to know how, I’m saying that with exposure I have gained intuition, and as a result have learned to prompt better.
Ask an LLM to write powershell vs python, it will be more accurate with python. I have learned this through exposure. I’ve used many many LLMs, most are tuned to code.
Currently enjoying llama3.3:70b by the way, you should check it out if you haven’t.
And when the search engines shove it in your faces and try to make it so we HAVE to use it for searches to justify their stupid expenses?
Just scroll past it? I just assume it’s going to be wrong anyway.
Use something else.











