

I’m currently writing a CLI tool that handles a specific JSON data format. And I also want to give the user to get a slice of the item array of the file. It’s a slice in form of --slice START:END through commandline options. So in example --slice 1:2.
- Should I provide a 0 based index for the access or a 1 based index? In example
--slice 1:2with 0 based index would start with the second element and with 1 based index it would start with the first element. - And would you think its better to have the
ENDto be inclusive or exclusive? In example--slice 1:2would get only one element if its exclusive or it gets two elements if its inclusive.
I know this is all personal taste, but I’m currently just torn between all options and cannot decide. And thought to ask you what you think. Maybe that helps me sorting my own thoughts a bit. Thanks in advance.
I think it would depend on the typical user base and how the rest of the cli operates. If it’s typical array work or your users are typically programmers or otherwise know computing, then stick to 0 based indexing. If they’re users of spreadsheets and rarely interface with zero-based indicies, then stick to what they know. Just document it well enough for everyone!
I’d also think inclusive is more intuitive. If they only want one element, then they can provide the single element, otherwise they get the full range.
Although, if your cli is trying to mimic another programming function. If it’s very clear that’s the intent, then follow the functionality of the parent function.
First, thanks for the answer. As for the user base, its actually gaming oriented and they typically do not interact with 0 base. So I guess that makes for an obvious choice. And at the moment its also “inclusive”. To get one element user needs to
2:2. If user gives only one element, such as2, then I could convert it into2:2, to get one element. Sounds logical, right? Sorry for having so many follow up questions, my head is currently spinning.Do you think this interferes somehow with the logic of a “missing” slice element, which would default to “the rest of the list”. In example
2:would then get the second element and until rest. This is the default behavior in Rust.If I have a 1 based index, how would you interpret the
0? Currently program panics at Argument interpretation phase.How much time do you have to program in edge cases? If I had the time and it were me, I’d parse for single number and return a single element. A single number with colon would give the front/back portion of the list accordingly. And two numbers gives the inclusive range.
Then in terms of if you get a zero, swap to zero index mode since they clearly want the start of the list or reject the command explaining the argument isn’t zero-based (probably best to reject just for consistency).
The docs/help page will be key here. That and consistency across your app when it comes to zero vs one indexing.
I think that I’m going with these approaches. For the ‘0’, I’m now accepting it as the 0 element. Which is not 0 based index, but it really means before the first element. So any slice with an END of 0 is always nothing. Anything that starts at 0 will basically give you as many elements as END points to.
0:is equivalent to:and1:(meaning everything)0is equivalent to0:0and:0(meaning empty)1:0still empty, because it starts after it ended, which reads like “start by 1, give me 0 elements”1:1gives one element, the first, which reads like “start by 1, give me 1 element”
I feel confident about this solution. And thanks for everyone here, this was really what I needed. After trying it out in the test data I have, I personally like this model. This isn’t anything surprising, right?
I personally find it easier for non programmers to use a START:LENGTH model.
3:5 is (up to) 5 elements starting at the third.
1:1 is just the first element
Any 0 is invalid
20:2 is elements 20 and 21
It eliminates inclusive/exclusive questions.
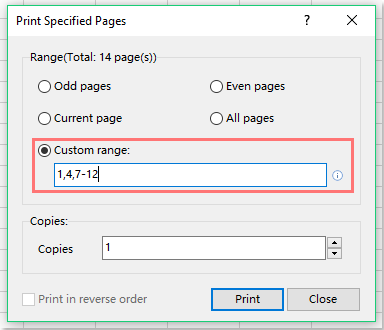
Microsoft’s print dialog offers custom ranges of pages in an intuitive way, see above
You could demonstrate the numbering system for the users, maybe once at startup. Make it the first thing they see
No, that’s not an option here. This is a commandline program, something like
grepin example. And this slice is just one of the many features the user could use to refine the output.I mean to say the numbering system 1, 4, 7-12 to indicate slices of data, not the UI 🤣
other possibilities: 1, 4, 7-rest (“7 through the rest of the slices”) or 1, 4, 7… (“7 through the rest of the slices”)
and provide it as sample input to the user when they first try to print something, that should give them an idea of how to use your numbering system

Anybody capable of using a CLI knows that the right answer is:
- index from 0
- end is exclusive.
Dijkstra points out why: https://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD831.html
I agree with that other comment which argues to set it as the users expect. I think the 1 based is logical here
But contrary to that, often ‘0’ is also used as the last element or points to “the entire match” in example. Whatever that is. I feel like outside of programming languages, for the end user, its not that clear of an answer. Why I created this topic.
I’ll read the linked article and rethink this topic. Maybe introducing another option to make the index 0 based (or the other way 1 based).
often ‘0’ is also used as the last element
Where? I’ve literally never heard of this convention.
RegExes. For instance, in JavaScript,
'foobar'.match(/(foo)(bar)/)is['foobar', 'foo', 'bar']Now that you ask, I don’t have any example of this. I know program
headhas negative numbers to access from the last element backwardsls -1 | head -n -1, but it does not start by 0. So yeah, the 0 as last element might be not as common as I thought to be.-1 is common. I’ve at least seen it from python.
Came here to post this. You need a very good reason to break with Dijkstra
I’ve been working on this problem for my own language, and have landed on something more clear than just following a convention. Basically you use
[]and()to specify if the left and right bounds are included or not (based off of interval notation: https://en.wikipedia.org/wiki/Interval_(mathematics)#Including_or_excluding_endpoints). e.g. for your case--slice [1:5) # include the left index. don't include the right index --slice [1:5] # include both left and right index --slice (1:5] # don't include the left index. include the right index --slice (1:5) # don't include the left or right indexpotentially not relevant to your case, but my version supports an
endkeyword which you can do math on, similar to python’s negative indexing[2:end-3] # start at index 2 (included) and go through till the third from last index (included) (end-3:end] # start at the third from last (excluded) and go to the end (included)Personally I’m a fan of 0 indexing, but for your context, I think it would depend on how the user sees what they’re slicing. E.g. if it was pages with page numbers, the numbers would indicate if it was 0 or 1 index based. If there’s nothing to actually show the user, I think picking something reasonable and documenting it well is probably the best bet.
That’s still following a convention
Sorry for late reply. I actually like the idea to use words to indicate
startandendas well. But with additional “math like” features it gets a little bit complicated to parse for simple slicing as an option in a program. It makes much more sense to do this flexible thing in a language. BTW its shouldn’t be needed to have anendif you already have a negative number.I use the empty string as indicator for start or end
"..2"(BTW I switched to..separator after long thinking, reading arguments and debating with myself).Just as an idea, you could provide another variable
midso one could start counting from there(mid+2:end). And man the idea sounds really elegant to use[or(to indicate if the number is inclusive or exclusive. But I fear it could be a little bit confusing and people could forget which one is which. I would rather prefer special characters that are not used otherwise. In example both sides are always inclusive and there is a special character before or after the number to indicate its exclusion. A character that is not used otherwise in numbers or slices and is representing the exclusion unmistakably, and I have absolute no idea what this could be.I have to say the usage of brackets to indicate its inclusion or exclusion is creative thinking!
Ruby/Crystal seem to have P … Q for inclusive ranges and P … Q for right-exclusive ranges.
Hi, I am not sure what you mean by this, because
P … Q for inclusive ranges and P … Q for right-exclusive rangesboth look identical to me. I have to check out those languages to see how they handle it, but I am already set.
You’re writing a CLI tool to handle JSON data. Just making sure: You know
jqexists, right?Right, but this tool does more than just what
jqdoes. The file format has some specifics like default values in global header area for specific data and so on. it provides lot of special features optimized for the end file format that uses JSON data.Edit: To add an example what I mean is, JSON is like XML. It allows you to define a end format. JSON and XML are “encoded data”. Just being able to read JSON or XML is not enough to understand the format in its detail, if there are some complexities to it.
I know some programming languages use : for ranges and it is more legible if you support negative indices, but I think START-END is more natural reading and I’d use : for START:COUNT instead, e.g. 3:4 for 4 elements starting from 3, so elements 3,4,5,6 or 3-6.
You can even support both formats! (Feature creep warning)
A dash is a bit problematic from practical point of view. In example I allow single numbers without a colon like just
6which would be interpreted as6:6. And each element is optional as well, which would make-6either be a negative number, an commandline option or a range? Some languages also use dots..instead. If I want ever support negative numbers, then the hypen, dash or minus character would be in the way.I mean I could just do a duck typing like stuff, where I accept “any” non digit character (maybe except the minus and plus characters) with regex. Hell even a space could be used… But I think in general a standardized character is the better option for something like this. Because from practical point of view, there is no real benefit for the end user using a different character in my opinion. Initially I even thought about what format to use and
a colon is pretty much set in stone for me(Edit: this part didn’t age well) I recently switched to..after long thinking.



