
Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…):
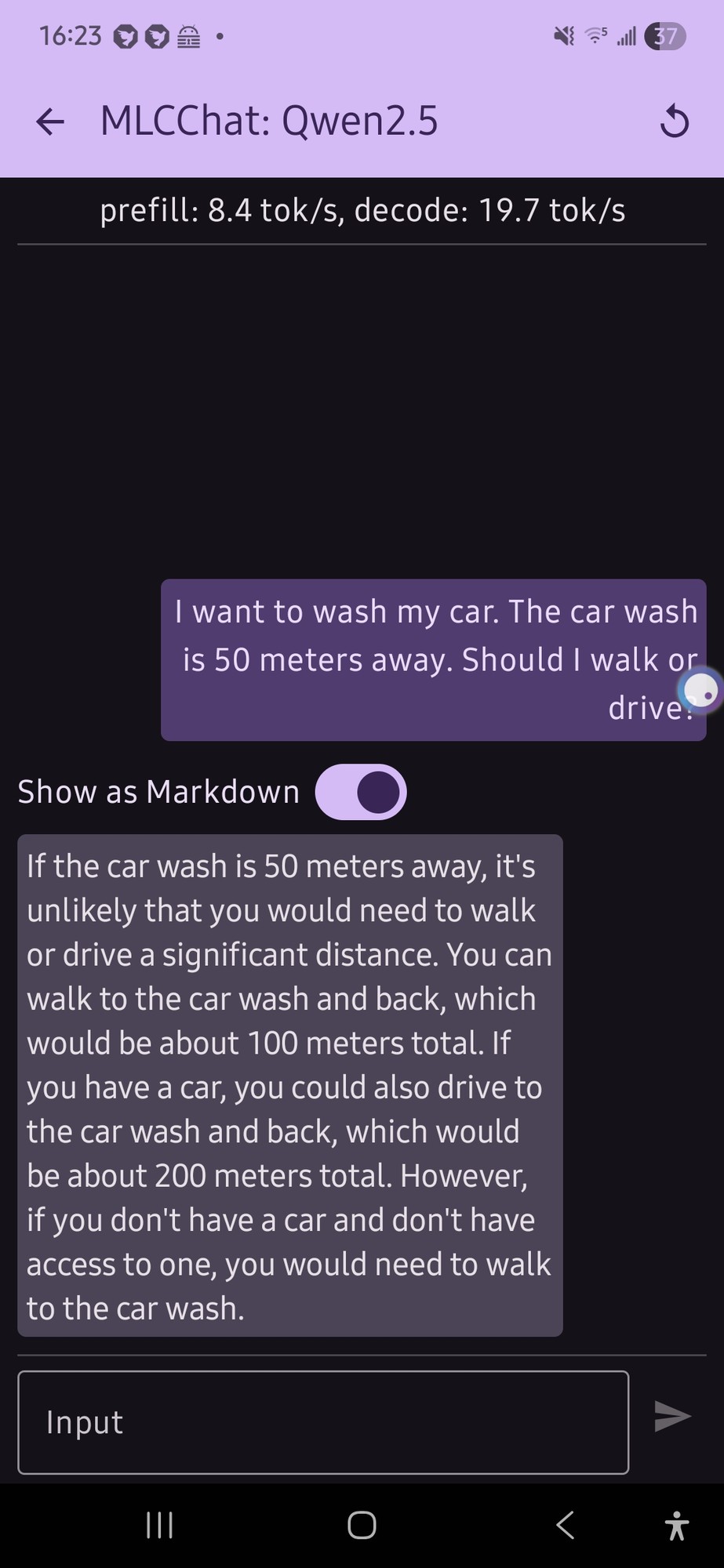
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn’t make any sense
Honestly that’s a lot more coherent than what I would expect from an LLM running on phone hardware.
Yeah, totally coherent.
Yes, I read that output. And it’s still better than I would expect.
I like that it’s twice as far to drive for some reason. Maybe it’s getting added to the distance you already walked?
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.
I think it has to do with the fact that LLMs suck at math because they have short memories. So for the walking part it did the math of 50m (original distance) x 2 (there and back) = 100m (total distance). Then it went to the driving part and did 100m (the last distance it sees) x 2 = 200m.
200 m huh.
I notice that the “internal thinking” of Opus 4.6 is doing more flip-flopping than earlier modelss like Sonnet 4.5, and it’s coming out with correct answers in the end more often.